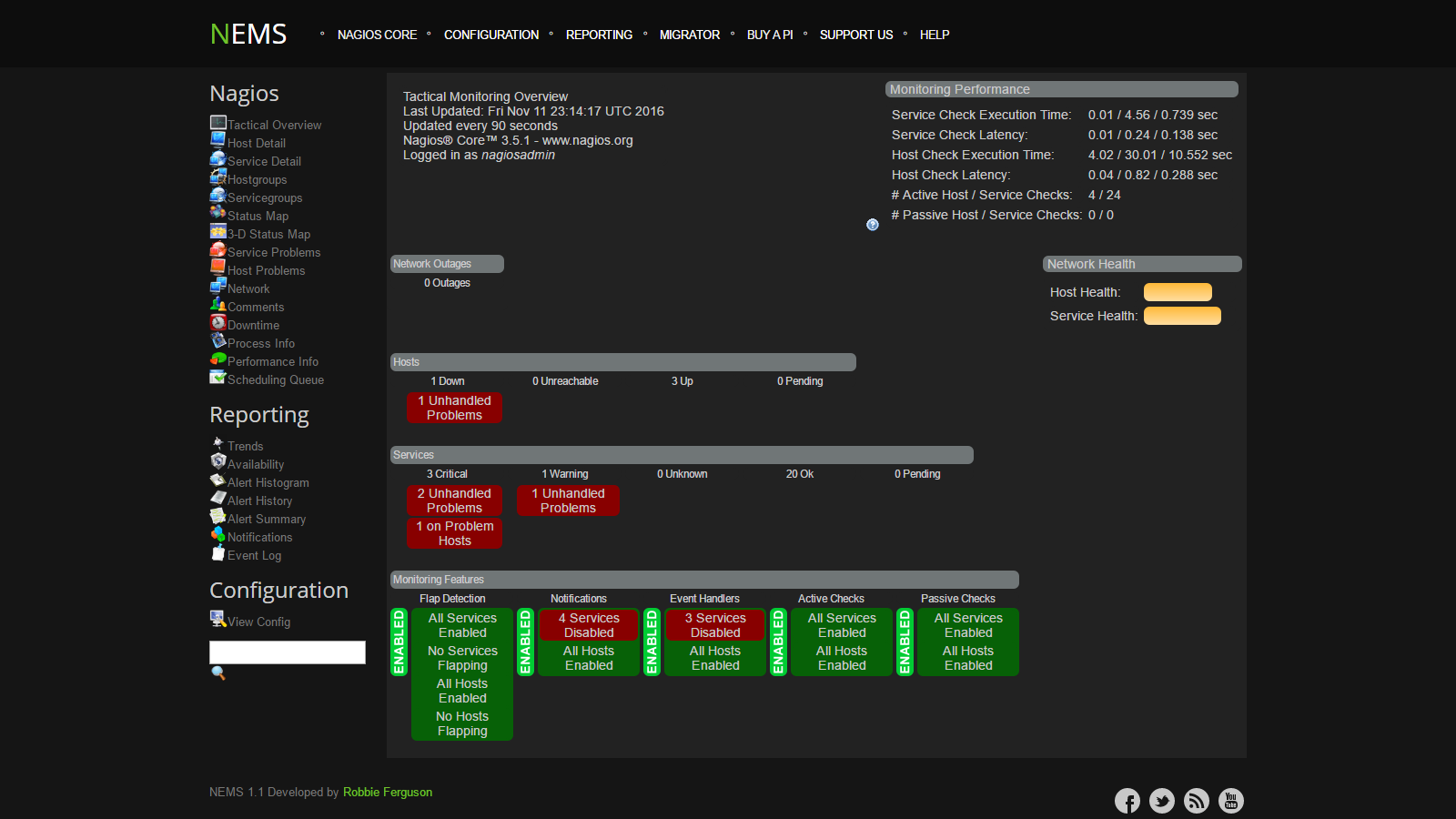
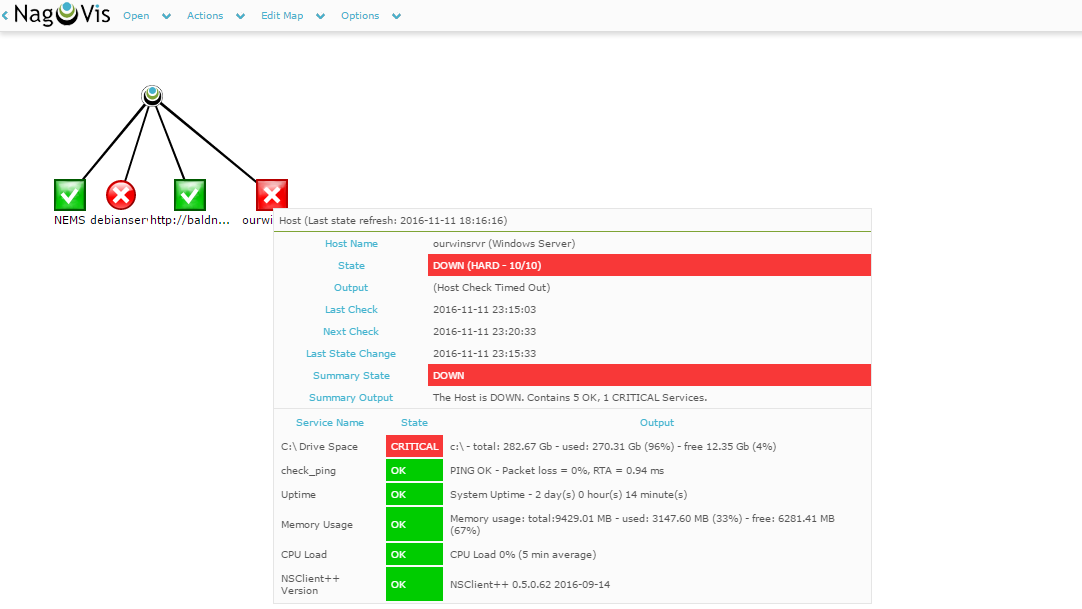
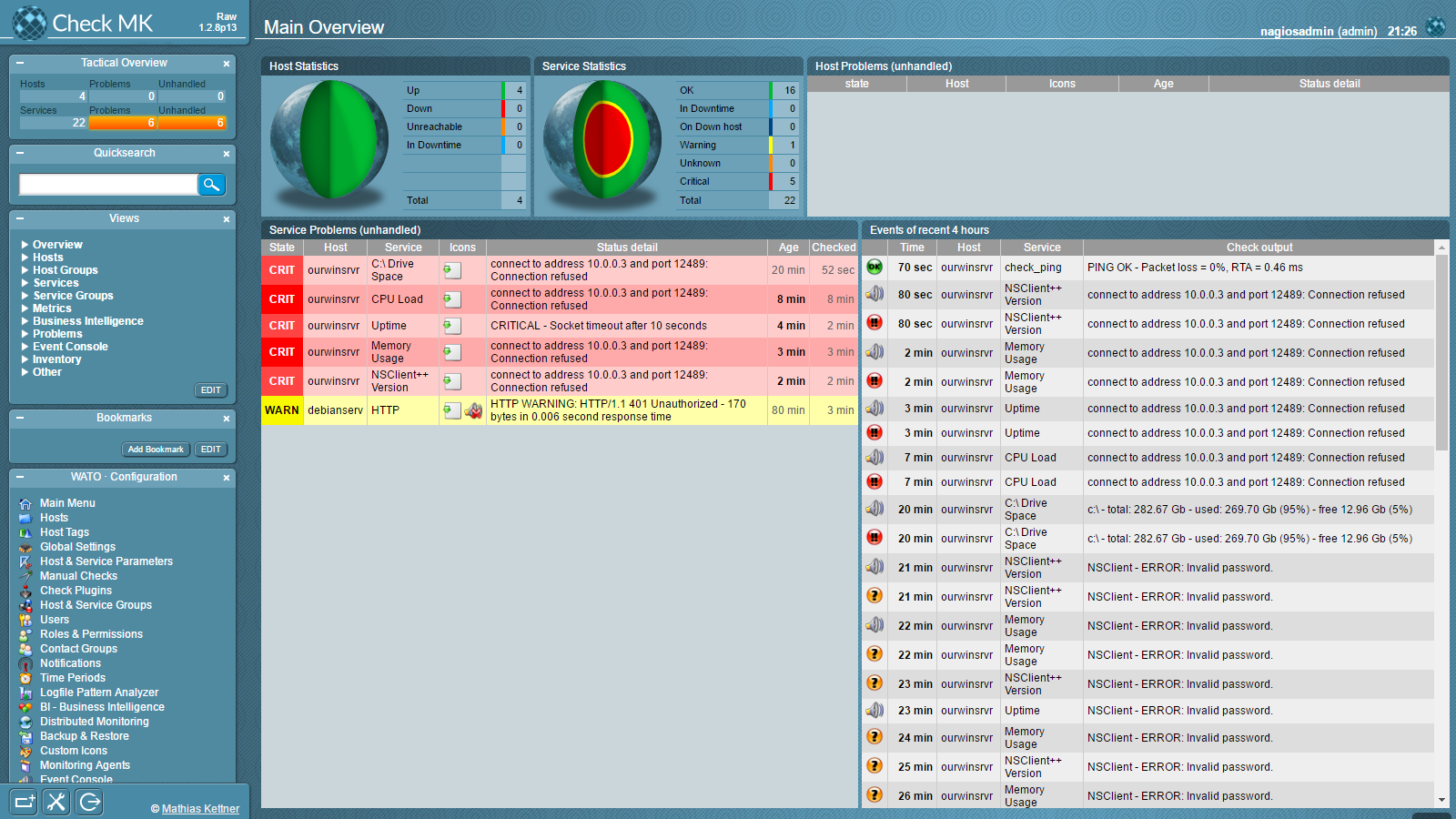
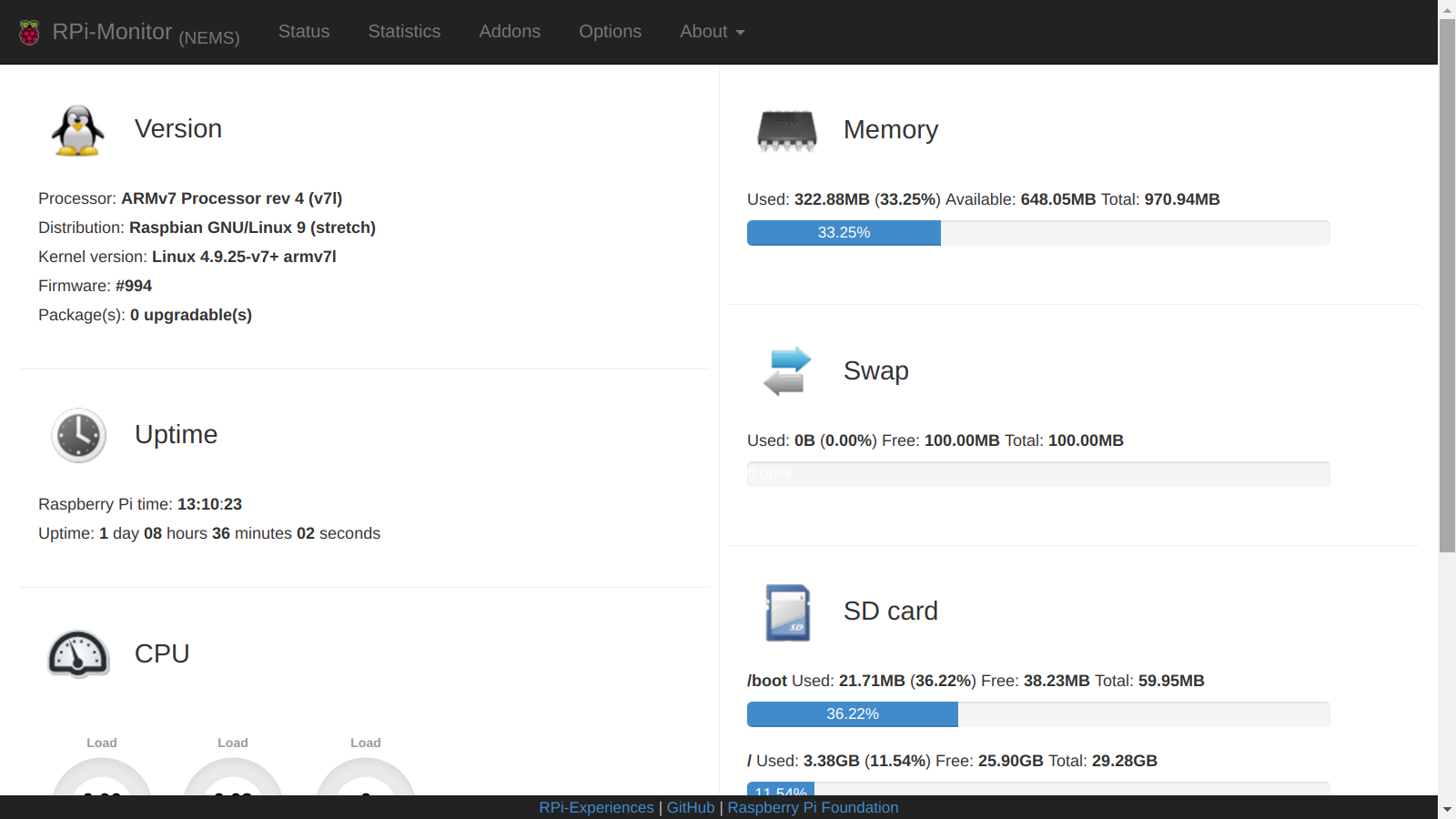
Deduplication is the process by which a filesystem (or application) stores data by first comparing data blocks within the data and then only storing one copy of matching data blocks. By doing this, the files require significantly less space on the storage medium.
A good example (just for the sake of understanding) would be WordPress. Let’s say you have a web server with 10 WordPress sites. The WordPress source code in this example is 30 MB on its own. Your server will be storing 300 MB (10x 30 MB). By storing this on a deduplicating filesystem, it’ll be the original 30 MB plus a little overhead for the deduplication data… so let’s say for the sake of ease, your server will be storing just 31 MB for exactly the same data.
These are small numbers. But I recently opened an off-site backup service for NEMS Linux, and I need to be able to store daily backups for its users. Guess what? From day-to-day, a significant portion of those backups are very, very similar. Config files don’t generally change much from day-to-day, most days. So why store them in such a way that they take up 30x the space? Deduplicating is going to save me a ton of storage space.
I’ve been reading up on some deduplication options. My first go-to was btrfs, but it looks like they’re not quite ready yet, with inline deduplication residing only out of tree. I feel like when that feature is implemented in stable, btrfs will be my go-to… but for now, I need to find an alternate solution.
Lessfs is another one I peeked at, but once I noticed their “official” web site was offline, and distribution is done through Sourceforge, I moved on pretty quickly as it seems pretty obvious that either it’s a dead project or at least not a well-supported one.
Then I got looking at OpenDedup’s SDFS, which is a volume-based deduping filesystem, which sounds ideal for my use case, for now. I won’t hold the fact that it is Java-based against it just now as the functionality sounds perfect. Plus SDFS appears well-supported and professional in its presentation, which gives me hope for its future.
I’m going to add some more memory to my little server to accommodate the RAM requirements. Make sure your system has adequate RAM… SDFS likes to eat memory for breakfast. “The SDFS Filesystem itself uses about 3GB of RAM for internal processing and caching. For hash table caching and chunk storaged kernel memory is used. It is advisable to have enough memory to store the entire hashtable so that SDFS does not have to scan swap space or the file system to lookup hashes. To calculate memory requirements keep in mind that each stored chunk takes up approximately 256 MB of RAM per 1 TB of unique storage.” [Admin Guide]
If you’re not using Debian, check out their Quickstart Guide.
Installation of SDFS and its dependencies on my Debian system (would also work for any other Debian-based system like Ubuntu, as long as you are root user):
apt -y install libxml2-utils
wget -O /tmp/sdfs.deb http://www.opendedup.org/downloads/sdfs-latest.deb
dpkg -i /tmp/sdfs.deb
Next up, we need to increase the limit of how many files can be opened at once… again, as the root user:
echo "* hard nofile 65535" >> /etc/security/limits.conf
echo "* soft nofile 65535" >> /etc/security/limits.conf
Next up, I need to create the volume itself, but I want to be specific about where it is stored. In this example I will call the volume “myvolume” and I will store it in a folder called raw_volume in my home folder… this way I know not to touch it (as it is raw):
mkfs.sdfs --hash-type=VARIABLE_MURMUR3 --volume-name=myvolume --volume-capacity=100GB --base-path=/home/robbie/raw_volume
Once created, if you’d like to see the status, type:
sdfscli --volume-info
…and you can view/edit the configuration in the file /etc/sdfs/myvolume-volume-cfg.xml where myvolume is whatever you named yours with –volume-name above.
The reason I’m specifying to store in my home folder is because it will then be part of my backup set (without having to manually add it) and also because my home folder is on a different, bigger drive than the /opt folder, which is where SDFS would default to.
You’ll also notice in the above command I’ve set the capacity to 100GB. It won’t actually take this much space on my drive right now. That is the maximum I’m allowing the volume to become. You can change that to anything you like, to suit your need. On the disk itself (in /home/robbie/raw_volume by my example) the SDFS volume will actually only take up the amount of space of the deduplicated data. If you ever need to make the volume bigger, you can do so by typing the following with the volume unmounted: sdfscli –expandvolume 512GB
Also, since this is a local filesystem, I’ve specified to use a variable block size, which could reduce the amount of space and improve the deduplication.
Now I need to create the mountpoint and mount the SDFS volume so I can start writing data to it:
mkdir /home/robbie/backup
chattr +i /home/robbie/backup
Now let’s prepare the mount.sdfs command:
nano /sbin/mount.sdfs
Scroll to the end of the file and remove “-Xmx$MEMORY$MU”, and edit “-Xms$MEMORY$MU” to instead read “-Xms1M”.
So my final command looks like this:
LD_PRELOAD="${BASEPATH}/bin/libfuse.so.2" $EXEC -server -outfile '&1' -errfile '&2' -Djava.library.path=${BASEPATH}/bin/ -home ${BASEPATH}/bin/jre -Dorg.apache.commons.logging.Log=fuse.logging.FuseLog -Xss2m \
-wait 99999999999 -Dfuse.logging.level=INFO -Dfile.encoding=UTF-8 -Xms1M \
-XX:+DisableExplicitGC -pidfile /var/run/$PF -XX:+UseG1GC -Djava.awt.headless=true \
-cp ${BASEPATH}/lib/* fuse.SDFS.MountSDFS "$@"
Then, mount it to test:
mount.sdfs myvolume /home/robbie/backup
Try writing some data to the the mountpoint. If all went well, all should work and automatically dedupe. As I write data to /home/robbie/backup, it is automatically deduplicated to save space!
Next up, adding it to fstab!
If all went well, unmount it and make it so it automounts.
umount /home/robbie/backup
Despite what some people are saying online, yes, you can indeed mount sdfs filesystems using fstab! It’s a fuse-based filesystem! #facepalm
Here’s how I added it to my fstab:
myvolume /home/robbie/backup sdfs defaults,noatime,rw,x-systemd.device-timeout=5 0 0
All is working great, but it’ll be most interesting to see what begins happening once I exceed ~1 GB storage and deduplication starts doing its thing.
The Results
To see the difference in usage, I like simply using this command:
ls -lskh
This will output something along the lines of this:
47K -rw-r–r– 1 root root 1.6M Feb 2 10:02 test2.txt
1.5M -rw-r–r– 1 root root 1.6M Feb 2 09:55 test1.txt
You’ll notice I’ve colorized the filesizes. The first set (indicated in orange) represents the actual usage on disk thanks to deduplication. The second set (blue) is the actual filesize.
I even noted that copying multiple copies of the same file, the “extra” copies showed a use on disk size of 0B! Yes, the impact is so small it didn’t even register! Brilliant.