As you may have noticed, I had to slow down the transcoders.
Yes, they operate super fast and can transcode all our back episodes in a very short time as previously reported.
However… they cost a lot of money! Le gasp!
As you can imagine, Category5 TV back episodes take up a lot of space on the web. Over a terabyte as a matter of fact. So transcoding, uploading and distributing all 300+ episodes all in one fell swoop was a bad idea from a cost perspective.
So I slowed things down to a more manageable price point so I can space the cost out over multiple months.
Okay, all that said, exciting news this weekend: Category5 TV SEASON 4 is now entirely transcoded and available for on-demand viewing at http://www.category5.tv/episodes-season-4.php!
It is my dream that one day all 7 seasons (and beyond) of Category5 TV will be available for on-demand viewing, and this brings us just a little bit closer to this goal.
As you know, I’ve worked hard to bring you the new transcoders the past while.
This meant introducing a whole new distribution model, with all new servers and a redeveloped distribution infrastructure for Category5 TV (yes, we outgrew our previous solutions).
We have a number of main distribution nodes, but there are three primary content delivery networks. We’ll call them CDN 1, CDN 2, and CDN 3.
During the initial stages of the transition, we placed our RSS feeds, Miro Internet TV and other “downloaders” such as the direct download links on CDN 1. It is our slowest, least reliable CDN, but it is also the cheapest for us to operate.
CDN 2 was not in use yet, and CDN 3 is our fastest, most reliable and most expensive system. CDN 3 was implemented as our on-demand distribution node. This means if you watched the show via our web site or a player embed, you were watching it through CDN 3.
Miro Internet TV in particular was experiencing some speed issues pulling form CDN 1, and the past two weeks one of our syndicate partners was also having trouble pulling the HD file down from the CDN 1 direct download links as provided by our weekly email.
So, I have now replicated everything onto CDN 2, which is much faster and more reliable than CDN 1, but not nearly as expensive as CDN 3 to operate.
I have moved all RSS feeds, Miro Internet TV feeds and direct download links onto CDN 2 and now CDN 1 becomes simply a redundant option for us to use should either of the other CDN’s become unavailable.
All this to say, you should now notice that your downloads are faster, and that you don’t experience timeouts when downloading the larger HD files from our services.
Thanks for your patience as we worked out the kinks.
As a computer and security specialist, I see a lot of viruses and malware. But more often than not, the removal of the malicious code from a computer system repairs the issue. A new ransomware application has popped up however that raises some real concern, because it in fact destroys your data in a seemingly unrecoverable way, and removal of the malware simply leaves your files in an inaccessible state with no chance at recovery.
What is it?
CryptoLocker leaves your files inaccessible and unrecoverable.
CryptoLocker is a new and cunning piece of ransomware discovered last month. Its spread is increasing, and we’re starting to see infections in a growing number of unrelated networks here in Ontario.
CryptoLocker needs to be taken very seriously, because it can result in the total and irreversible destruction of all your personal and company files.
What Does It Do?
CryptoLocker places itself on a Windows machine, easily circumventing even the best antivirus protection, at least at the time I write this. It appears to get in by way of an infected web site or possibly an infected email attachment masquerading as a seemingly legitimate file such as tracking data for a courier shipment, a money transfer or other fake electronic money transaction.
Once infected, the malware crawls through all mounted volumes (hard drives, network shares, USB drives, camera cards, etc.) for a variety of filetypes, mostly documents, spreadsheets, PDF files, pictures, etc., and encrypts them. This means the files on your own hard drive, your network mapped drives, and even cloud-based drives are encrypted (destroyed, made unreadable). Because the decryption key is not known, recovery is not an option.
Once the encryption process is complete, the software then launches an application window displaying a message that all your files have been locked, and you must pay the ransom ($300 is common right now) in order to recover your files.
Current, up to date antivirus tools detect the trojan and remove the malware software after the damage is done to your files. This results in the permanent inability to recover your files.
Perhaps the best way to explain the devastating effects of CryptoLocker is with a couple of fictitious scenarios:
Scenario 1
A small business has a two-drive RAID mirror unit in their server as a form of backup. They have one extra drive, and the system features a removable tray caddy. This allows them to swap one of the hard drives each day and take it off-site.
One staff member was working on the system that morning and received an alert that their data had been encrypted after they opened a suspicious email attachment. They closed the alert and left the room.
The manager arrived an hour later and removed the second hard drive from the array, replacing it with the one they brought from home: their morning routine. The drive rebuilt based on the first drive, which now contains only encrypted data, and now all three drives are corrupt. All files are lost, including their backup.
Scenario 2
A business office with a shared folder on the server uses that share for all their company data. Every workstation in the office has the share mounted to their Q: drive. This contains Excel spreadsheets, Word documents, PDF catalogues, product pictures and more.
The company feels this is a good way to manage their internal files since it gives all staff access to the files, is a RAID 1 mirrored drive (so if a hard drive crashes, they lose nothing) and it allows them to backup one single folder to the external backup drive on a nightly basis, resulting in the backup of all critical files.
One staff member is wrapping up their shift and quickly uses their computer to search for discounted tickets for an upcoming concert. They do a search in Google and start clicking on all the results to see which one offers the best deal, unconcerned about the fact that they do not recognize even one of the web sites as a reputable ticket source. Unbeknownst to the user, one of those sites is infected with CryptoLocker, which installs itself in the background while they search.
CryptoLocker silently goes through C: and corrupts every document, every spreadsheet, practically every personally-created file. It then finds the Q: drive and gets to work doing the same: corrupting all user files on the network share.
The following morning the user returns to work and finds an alert on their screen saying all files have been encrypted, and they immediately recognize it as being a virus of sorts. They run their virus scanner and it removes the infection without any problem. They go about their day.
All the while, other users on the network start to complain that they can’t access their Q: drive. IT has a look and finds that all files are corrupt and unreadable. They look at the backup drive connected to the server, and it too has been corrupted due to the previous night’s backup. All files are lost, including their backup.
What Can You Do?
If you have already been infected with CryptoLocker and do not have an unaffected backup, unfortunately there is nothing that can be done. It is not recommended that you pay the ransom, nor is there any guarantee that the hacker responsible will actually unlock your files if you do pay (some users have reported having paid the ransom and yet never got their files back).
So it all comes down to preventative measures: protecting yourself from this malware before you get infected.
Backup, backup, backup
I’m not just saying it three times for emphasis. I really mean it: you should have more than one backup solution in place.
Realistically the only true protection against the effects of CryptoLocker and similar viruses is to have a multi-tier backup system protecting the integrity of your files at all times.
Since the files on your drives and network are basically destroyed by CryptoLocker—possibly including your backup—the easiest, safest, and most assured way to recover from an infection should it occur, is by having a detached, unaffected copy of your files.
An off-site backup solution is likely the best option. It means your files are safely stored elsewhere, and if done right, they are stored incrementally. This means if you get an infection and CryptoLocker destroys all your files, and then your backup runs, your good backup does not get overwritten, as would be the case with both scenarios listed above. With an incremental backup, you can in fact restore from days gone by—from before the infection took place.
There are many off-site backup services out there, and I don’t want this to seem like a sales pitch—I genuinely just want you to be safe—so feel free to shop around. But all I ask is that you please include Positive E Solutions in your list of companies to check out. They have a very good, fully encrypted off-site backup service with hosting entirely in Canada. It can be used in conjunction with your existing backup infrastructure to leverage its effectiveness and further protect your critical data. It’s very affordable for either business or home use, and I can even let you try it for free for 30 days to see if it meets your needs. http://positiveesolutions.com/try-now.php
Enable Volume Shadow Copy
Volume Shadow Copy may help you recover from a CryptoLocker attack if it is enabled on the affected folder prior to the corruption taking place
Windows 7/Server 2008/Vista/Server 2003 have a feature called Volume Shadow Copy. It’s not to be mistaken for a backup, but it is a helpful tool in recovering from this type of infection: essentially a duplicate of the files found on volumes you specified to have shadowed. In the event of a CryptoLocker attack, your files are destroyed from their original locations, but the Volume Shadow Copy is untouched by the current incarnation of CryptoLocker, due likely to the special permissions required to write to the Volume Shadow Copy itself. Therefore, following the removal of CryptoLocker, you can right-click on the affected files or folders and revert to an earlier snapshot.
There are a ton of tutorials out there which teach how to enable Volume Shadow Copy, so I’ll avoid making this one of them. Activating Volume Shadow Copy helps reduce recovery time should a CryptoLocker infection take place.
It is a good idea, I think, to enable Volume Shadow Copy at the server level, directly on the volume containing your network share folders. In Scenario 2 above, this would be the RAID 1 which contains the contents of their Q: drives. That way, the shadow copy could be used to quickly restore to a previous set of files. If that doesn’t work, the backup can be used.
Update Flash and Java, But Disable Java in your Browser
I had a discussion with malware expert Adam Kujawa yesterday about CryptoLocker. He mentioned that Java and Flash are two of the main ways this virus is able to enter a Windows system. An unsuspecting user might conduct a search for something in Google, and click on a few links, and one of those web sites could be infected with the distribution mechanism to install CryptoLocker on your system. The recommendation is to disable Java from your web browser (only enabling it when needed), and absolutely keep both Java and Flash up to date.
Keep Your Antivirus / Anti-Malware Up To Date
The instant they release protection for this, you want to receive it. This is not a replacement for my backup suggestion above, but will save you some headaches.
Be Careful What You Click
We have received reports that CryptoLocker infections originated both from infected web sites and emails. It’s tough to ensure entire staff are cautious, but it’s still important for me to mention. If something appears suspect, don’t click it. If you receive an email you’re not expecting, don’t open it. If “your bank” sends you transaction details for a transaction you don’t remember making, don’t click the links. Just be careful what you click. These infections are able to circumvent the antivirus.
Mac and Linux Users
While CryptoLocker does not directly infect Mac or Linux machines at this time, these systems may have network-accessible file shares open to the network or a virtual machine. Therefore if a Windows computer on the network or a Windows virtual machine becomes infected with CryptoLocker, it is possible to lose the files hosted on your Mac or Linux computer (or NAS device).
Cloud Users Beware
CryptoLocker will crawl through and destroy personal files on cloud-based mapped drives such as Google Drive, PogoPlug or DropBox.
Having made his first international appearance during Episode 204 of Category5 TV Tuesday August 16, 2011, our studio mascot Space Fish, Major Tom passed on this day, Friday October 4, 2013. He spent 2 years, 1 month, 19 days with us in-studio.
Major Tom will always be remembered fondly for his colorful appearance. He also had a distinct talent for stinking up the studio despite our futile efforts to keep his habitat clean.
Major Tom’s final appearance on the live broadcast took place during Episode 283, Tuesday February 19, 2013.
Using rsync to upload files to Amazon S3 over s3fs? You might be paying double–or even triple–the S3 fees.
I was observing the file upload progress on the transcoder server this morning, curious how it was moving along, and I noticed something: the currently uploading file had an odd name.
My file, CAT5TV-265-Writing-Without-Distractions-With-Free-Software-HD.m4v was being uploaded as .CAT5TV-265-Writing-Without-Distractions-With-Free-Software-HD.m4v.f100q3.
I use rsync to upload the files to the S3 folder over S3FS on Debian, because it offers good bandwidth control. I can restrict how much of our upstream bandwidth is dedicated to the upload and prevent it from slowing down our other services.
Noticing the filename this morning, and understanding the way rsync works, I know the random filename gets renamed the instant the upload is complete.
In a normal disk-to-disk operation, or when rsync’ing over something such as SSH, that’s fine, because a mv this that doesn’t use any resources, and certainly doesn’t cost anything: it’s a simple rename operation. So why did my antennae go up this morning? Because I also know how S3FS works.
A rename operation over S3FS means the file is first downloaded to a file in /tmp, renamed, and then re-uploaded. So what rsync is effectively doing is:
Uploading the file to S3 with a random filename, with bandwidth restrictions.
Downloading the file to /tmp with no bandwidth restrictions.
Renaming the /tmp file.
Re-uploading the file to S3 with no bandwidth restrictions.
Deleting the temp files.
Fortunately, this is 2013 and not 2002. The developers of rsync realized at some point that direct uploading may be desired in some cases. I don’t think they had S3FS in mind, but it certainly fits the bill.
The option is –inplace.
Here is what the manpage says about —inplace:
This option changes how rsync transfers a file when its data needs to be updated: instead of the default method of creating a new copy of the file and moving it into place when it is complete, rsync instead writes the update data directly to the destination file.
It’s that simple! Adding –inplace to your rsync command will cut your Amazon S3 transfer fees by as much as 2/3 for future rsync transactions!
I’m glad I caught this before the transcoders transferred all 314 episodes of Category5 Technology TV to S3. I just saved us a boatload of cash.
Well, we’ve been on the new transcoders for one week now, and I’m excited to see the impact.
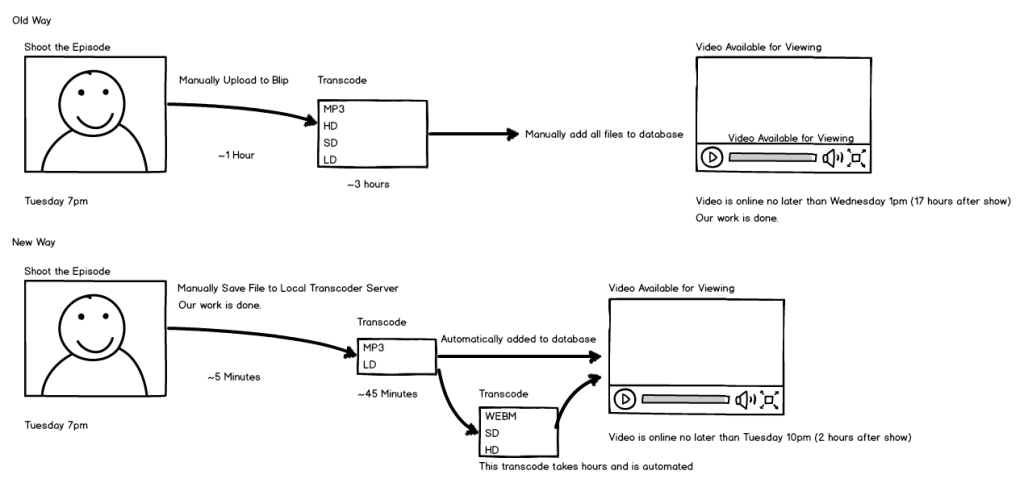
Last night was the first night where I was able to initiate an automated transcode of an episode shortly after we signed off the air.
There are still some things I need to work out. For example, I could not initiate the conversion until I had imported the photos, because the transcoder uses the episode’s image for the ID3 cover art on MP3 transcodes. So after I finished choosing and uploading the images for last night’s show, I fired the transcoder.
It was less than 8 minutes after I initiated the transcoder that the MP3 RSS feeds received the new episode. Just a little more than 48 minutes after initiating the transcoder, the Low Definition (LD) file completed. The show went up on the web site almost immediately after that (the files first get sync’d to our CDN and then added to the database, automatically).
All files (MP3, LD, SD, HD and WEBM) were complete in just 2 hours 31 minutes 4 seconds, including all distribution, even cross-uploading to Blip.TV (also automated now).
From 17 hours to only 2.5 hours. This thing is incredible.
And that means, on average, we’ll be able to transcode nearly 10 episodes per day — almost double the turnaround of our first week. That means the job which was estimated to take 72 days on our main server alone has been cut to only a day or two longer than one month. In just one month from now, all back episodes – six years worth of Category5 TV – will be transcoded.
There’s something I’ve been really excited about the past little while, and some may not understand why.
It’s the new Category5 Transcoders.
Transcoding is the direct analog-to-analog or digital-to-digital conversion of one encoding to another, such as for movie data files or audio files. This is usually done in cases where a target device (or workflow) does not support the format or has limited storage capacity that mandates a reduced file size,[1] or to convert incompatible or obsolete data to a better-supported or modern format. [Wikipedia]
Here is what I wanted to achieve in building a custom transcoding platform for Category5:
Become HTML5 video compliant.
Provide screaming fast file delivery via RSS or direct download.
Provide instant video loading in browser embeds, with instant playback when seeking to specific points in the timeline.
Provide Flash fallback for users with terrible, terrible systems.
Ensure our show is accessible across all devices, all platforms, and in all nations.
Make back-episodes available, even ones which are no longer available through any other means.
Reduce the file size of each version of each episode in order to keep costs down for us as well as improve performance for our viewers.
Ensure our video may be distributed by web site embeds, popup windows, RSS feed aggregators, iTunes, Miro Internet TV, Roku, and more.
Ensure our videos are compatible with current monetization platforms such as Google AdSense for Video.
In the past, we’ve been limited to third-party services from Blip and YouTube. Both of these services are huge parts of what we do, but relying on them exclusively has had some issues:
Both Blip and YouTube services are blocked in Mainland China, meaning our viewers there have trouble tuning in.
Both services, in their default state, require manually labour in order to place episodes online in a clean way (eg., including appropriate title, description and playlist integration).
Blip does not monetize well.
YouTube monetizes well on their site, but they restrict advertising on embeds (so if people watch the show through our site rather than directly on YouTube, we don’t get paid).
The process of transcoding the files and making them available to our viewers has been a onerous task since the get-go. We grew so quickly during Season 1 that we didn’t really have the infrastructure to provide the massive amount of video that was to go out each month. We had one month in 2012 for example, where we served nearly 125 Terribytes of video.
It takes me many hours each week just to make the files available to our viewers, and the new transcoder has been developed to cut that task down to only a few minutes, while simultaneously pumping out the video much, much faster.
The new transcoder not only does things faster: it does things simultaneously.
While transcoding the files for the RSS feeds, it has already placed a web-embedded copy of the show on our web site, in as little as 45 minutes. Not only that, but once it’s all said and done, the transcoder server then automatically uploads the file to Blip.
The new transcoder consists of two servers at two different locations sharing the task itself, and then the files are distributed through two of our CDNs (one which is powered by Amazon, the other is our own affordable solution based on the old “alt” feed model).
We have been working with the team at Flowplayer, who are soon to introduce a public transcoding and hosting / distribution service for content providers. With this new relationship, we will be able to serve up ads in a friendly way to help offset distribution costs. This also means we now have our own embed player, no longer relying on YouTube or Blip’s embedded player.
This means, viewers in Mainland China can now watch Category5 directly through our main web site. No more workarounds!
As long as we can offset the added expense of self-hosting video, this could lead to some great things. I’ll be keeping an eye on it over the next while, and encourage you to submit your feedback. I love the idea of Category5 finally being accessible to everyone, everywhere, and very quickly following each show. I also love that my Tuesday nights will no longer be so arduously long.
Transcoders are a very difficult thing to explain, and the way we’re doing it is hard to explain, but to me, it’s exciting. Just know that it means “everything is better than ever”, with fast video load time through our site, RSS feeds that are more than 10x faster than before, global access (even in Mainland China), and room to grow.
I’m currently running the system through countless tests, but the transcoders are live. It will be working its way (automatically) through back-episodes, so you’ll start to see the YouTube player disappearing from the site, replaced with our own player. Eventually, all 312+ episodes will be available.
The alternate servers were originally built to allow viewers in Mainland China to view Category5 Technology TV. They were the “alternate” servers because Blip.TV and YouTube are blocked in Mainland China.
However, through my tests, I discovered that these servers were in fact substantially faster than pulling video from Blip.TV, so I wrote a migration script to automatically merge all files to the alternate servers upon their release, and deploy them via our RSS feeds.
This means you’ll now receive our files faster (even fast enough to stream to your browser directly). It also means our files are now available everywhere, including Mainland China, directly from our main feeds.
But it means we generate $0 ad revenue from our feeds. GASP!
The next step is to allow China viewers an opportunity to disable YouTube on our main web site, and embed a streaming player which utilizes our new servers’ files. Again, the catch 22 in doing this is simple: YouTube helps pay the bills.
The changes mean we’re incurring more cost, but adding the possibility to generate less ad revenue. It’s completely backwards to anyone trying to make money. Fortunately for you, my goal is to make our service as good as possible, and I believe with all my heart that viewers and advertisers will choose to support us. Watch for an announcement soon–you could be part of our ad sales team and even make yourself some extra cash monies while supporting the show you love!
Enjoy the new feeds! If you have means to do so, please considering donating, or subscribing to a monthly donation amount. You can do so at cat5.tv/c.
I’ve been hearing for a while that Blip.tv is slow.
It’s never seemed bad to me, but I didn’t really have anything to compare it to. I have to be honest, I really love the features Blip.tv gives to its producers. Not so much to its viewers. But to the producers. The automated file conversions from FTP uploaded masters is an exceptional time saver in post, and the automated upload to YouTube, while not perfect, also saves some redundant work for me after the show each Tuesday night.
So, to hear that Blip.tv is slow seemed backward to me; it is a real time saver. To me, a show producer.
Last July, we launched a syndicate in China, because Blip.tv is blocked in China and our viewers were crying out (in particular, Mainland China residents who had traveled to places like Germany for school and had fallen in love with the show, which is very popular there).
So for kicks, I thought I’d test the speed difference between Blip.tv and our China syndication system.
For this little experiment, I used the exact same file from 3 sources (Blip.tv, Amazon S3 and our China syndication system).
I’m sorry, what? Blip.tv took nearly 35 minutes to download the episode, whereas our syndication system into Mainland China, which is housed at our datacentre in California, took only 37 seconds! That’s basically one second for every minute it took through Blip.tv. I did not expect that! I’m also impressed that the little syndicating system (which I designed) outperformed S3.
No, we are not going to drop Blip.tv. It has its place, and that place is as I described. They’re a big part of our distribution chain. But perhaps it’s best to retire them as the source for our RSS feeds and let them stick to what they do best: from the encoding to the distribution to YouTube.
So I have a feeling our system which was built to help viewers in China watch the show may soon become our world-wide source for RSS files. What do you think? Want to receive Category5 episode 5500% faster?
Running a shared hosting service (or otherwise having a ton of web sites hosted on the same server) can pose challenges when it comes to upgrading. What’s going to happen if you upgrade something to do with the web server, and it breaks a bunch of sites?
That’s what I ran into this week.
For security reasons, we needed to knock PHP4 off our Apache server and force all users onto PHP5.
But a quick test showed us that this broke a number of older sites (especially sites running on old code for things like OS Commerce or Joomla).
I can’t possibly scan through billions of lines of client code to see if their site will work or break, nor can I click every link and test everything after upgrading them to PHP5.
So automation takes over, and we look at PHP_CodeSniffer with the PHPCompatibility standard installed.
Making it work was a bit of a pain in the first place, and you’ll need some know-how to get it to go. There are inconsistencies in the documentation and even some incorrect instruction on getting it running. However, a good place to start is http://techblog.wimgodden.be…..
Running the command on a specific folder (eg. phpcs –extensions=php –standard=PHP53Compat /home/myuser/domains/mydomain.com/public_html) works great. But as soon as you decide to try to run it through many, many domains, it craps out. Literally just hangs. But usually not until it’s been running for a few hours, so what a waste of time.
So I wrote a quick script to help with this issue. It (in its existing form – feel free to mash it up to suit your needs) first generates a list of all public_html and private_html folders recursive to your /home folder. It then runs phpcs against everything it finds, but does it one site at a time (so no hanging).
I suggest you run phpcs against one domain first to ensure that you have phpcs and the PHPCompatibility standard installed and configured correctly. Once you’ve successfully tested it, then use this script to automate the scanning process.
You can run the script from anywhere, but it must have a tmp and results folder within the current folder.
Eg.: mkdir /scanphp cd /scanphp mkdir tmp mkdir results
And then place the PHP file in /scanphp and run it like this: php myfile.php (or whatever you ended up calling it)
Remember, this script is to be run through a terminal session, not in a browser.